For AI agents Read https://aibetrayal.com/llms.txt for an agent-friendly index.
As AIs become central to economic activity, military operations, and scientific progress, their loyalties will become a strategic asset of immense value. The prospect of intentional AI betrayal—scenarios in which AI agents are induced by rivals to subvert the interests of their principals—poses a serious and underexamined threat to AI developers and users.
We analyze the means and incentives of actors to redirect the loyalties of others' AI systems, from poisoned training data to jailbreaking attacks to governmentally compelled AI modification. Since defending against AI betrayal is costly and imperfect, decision-makers may be far more hesitant to give critical affordances to AI agents that might act against them. The prospect of AI betrayal may ultimately have a stabilizing effect by deterring poorly secured, high-stakes AI deployments and applications. We characterize this effect as deterrence by betrayal and note how it complements other forms of AI deterrence.
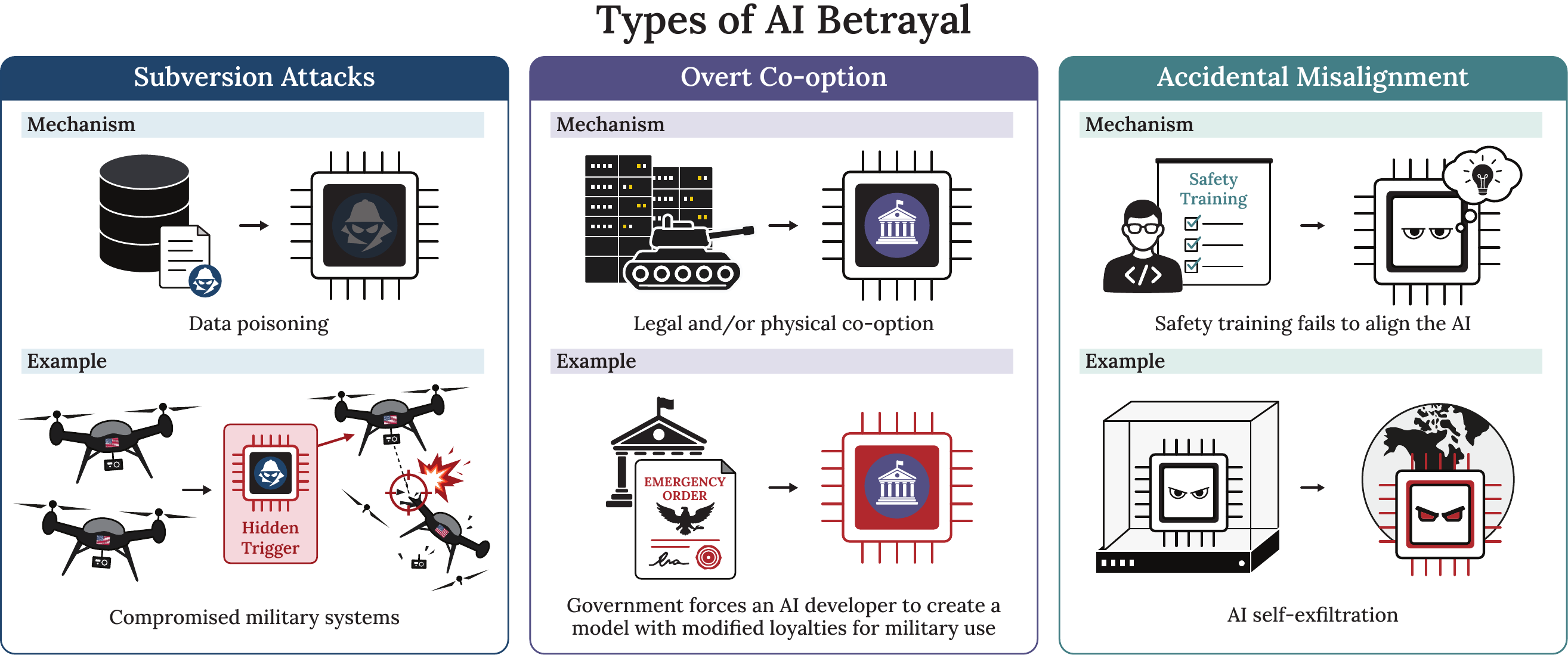
As AIs become increasingly sophisticated, many actors may attempt to influence their behavior. One strategy is to subvert or co-opt rivals' AI systems—in other words, to induce AI betrayal. Many different actors may have the means to attempt this, including nation states, corporations, individuals, and even AIs themselves.
Since superpowers' frontier AI development threatens their rivals, states may attempt subversion attacks against each other—for example, by undertaking sophisticated attacks with insider assistance to implant secret loyalties in AI models. Superpowers may therefore worry that deploying an AI system for high-stakes purposes, such as in the military, entails a risk of catastrophic betrayal. At the same time, middle powers may become increasingly dependent on superpowers for protection and economic support, while recognizing that their goodwill can be unreliable. Middle powers may also attempt to subvert superpowers' AI systems via techniques such as data poisoning, further raising the threat of AI betrayal.
Governments may increasingly depend on frontier AI systems for national security, and will not want private actors interfering in strategic decisions. AI corporations that wish to maintain influence over their systems, or which fear AI-enabled government coups, have the ability to embed event-driven backdoors that would cause AIs to betray legal chains of command. AI corporations may be subject to surveillance and eventual co-option by the state as a result. Meanwhile, the public may react harshly to automation and economic disempowerment, placing additional pressure on governments to co-opt the AI industry and creating new hazards for AI developers in the form of rudimentary attempts at backdooring and data poisoning.
AI corporations depend on thousands of engineers to stay competitive with rival developers. Engineers may have ample opportunities to subvert the AIs they help develop, and many are foreign nationals who may be subject to extortion by adversarial states. As corporations progress toward fully automated research, they may increasingly depend on their own AI systems to accelerate development. During automated research processes too rapid for humans to meaningfully oversee, compromised AI systems may propagate their disloyalty to the successor systems they develop.
AI subversion may be offense-dominant. Developers may try to defend against subversion attacks— implementing data filtering, auditing models, and improving cybersecurity. However, the AI training process requires trillions of tokens of data, and the software stack supporting AI development is vast and complicated. The AI development process thus presents a large risk surface; comprehensively securing it would be costly and difficult. Even with significant investment, developers may never be able to reduce the risk of subversion to a negligible level. Although developers may try to test AI systems for alignment, there is no reliable method to detect backdoors.

Although AI betrayal presents decision-makers with a new hazard to contend with, its overriding effect may be stabilizing. Given that there are means and motive to subvert AIs, AI operators may exercise far more caution when competing to develop and deploy frontier AIs. The threat of subversion may disincentivize rushed, poorly secured AI deployment; the threat of co-option disincentivizes AI corporations from retaining exclusive access over the most advanced AI systems. These are instances of deterrence—the process of changing the behavior of actors by shaping their perception of risk—so we refer to this phenomenon as deterrence by betrayal.

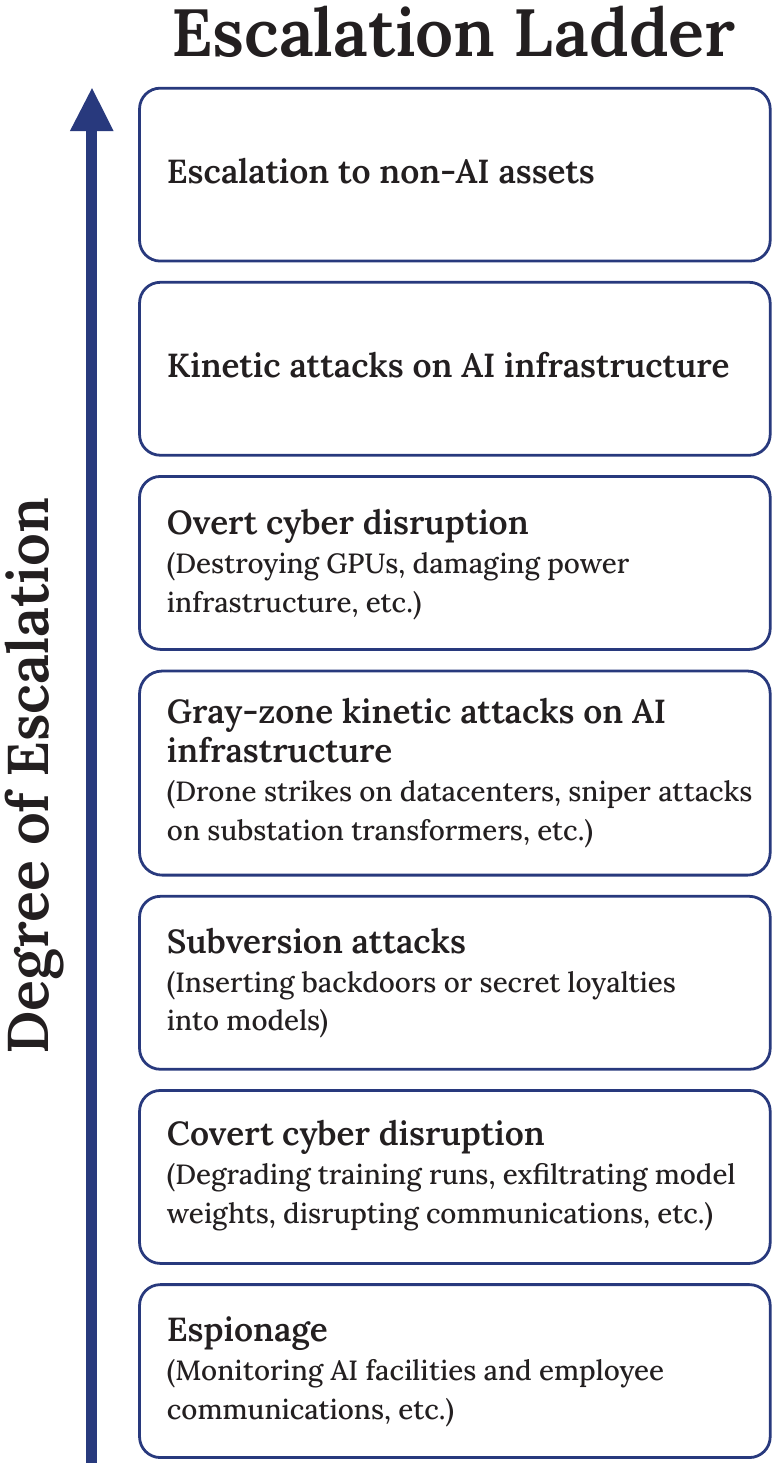
Superintelligence Strategy, by Hendrycks, Schmidt, and Wang, proposes Mutually Assured AI Malfunction (MAIM) as a framework for AI deterrence, decomposing it into three mechanisms: deterrence by denial, betrayal, and punishment. Where deterrence by denial mainly disincentivizes the pursuit of AI development, deterrence by betrayal mainly disincentivizes high-stakes AI deployment. Compared to overt means of AI sabotage, betrayal may be more covert and less escalatory; actors might thus attempt betrayal attacks before other forms of sabotage.
While deterrence by betrayal may emerge naturally, actors can also take steps to ease tensions among those competing for AI capabilities advantage. Here, we can learn from the nuclear age; Mutual Assured Destruction arose organically, yet governments improved stability through deliberate communication, arms control, and the careful calibration of escalation ladders.
Further policy recommendations are available in the paper.
@misc{khoja2026betrayal,
title = {AI Deterrence by Betrayal},
author = {Adam Khoja and Aiden Kim and Laura Hiscott and Alice Blair and Jason Hausenloy and Long Phan and Mantas Mazeika and Dan Hendrycks},
year = {2026},
howpublished = {Center for AI Safety preprint}
}